
This is an veeery naive experiment on language.
Assume that the ‘distance’ between two concepts is directly related to the number of times they appear together in written texts.
To simplify, lets limit ourselves to nouns.
Suppose we:
- Created a web page for each noun that has a distinct meaning in English. For example, father and parent could have a same page, but father and Father (God) could not. Each page would have several links to the other nouns.
- Set the value (the relative distance of the pages), either by:
- Parsing (using a computer) a comprehensive selection of texts, and counting the frequency those words come together. For example, in Text1 ‘father’ appeared 97 times and ‘son’ 42 times. So the value could be the sum, 139. From Text2, 225, from Text3, 5. Summing all, we get 369.
- OR Query Google for the two nouns, and register the number of results. This would have less control on the input.
A pagerank would give the relative important of concepts.
There are issues in defining what constitute a noun. Is ‘dog food’ one noun, or two? It would seem to be more interesting to define ‘dog food’ as different from dog and food. Let’s not waste much time on this and carry on.
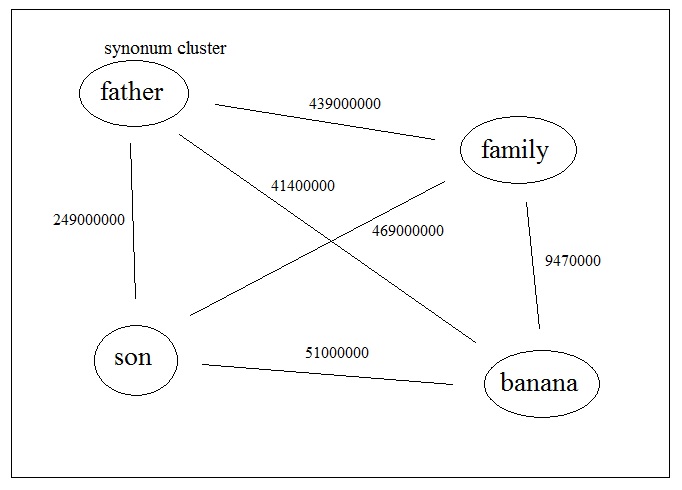
Example of a noun network. The numbers in the links are the results from Google when searching both words together.
Still with me?
Now build a web crawler to navigate this network of nouns. Use, for example, the shortest route (the highest value in the picture above). You should navigate from node to node though the link with the highest value.
Say, if you start with ‘father’, you would get for 3 jumps
father
family
son
family
But what does this do? Well, navigating through this network would be a rudimentary way of thinking.
Think about it, going from one concept to the other, in a netword that has a measure of distance between concepts could allow you to produce reasoning. Isn’t that how we do it, by listening to a word and pulling threads that are related to it?
In the case of parsing texts, by feeding more diverse texts into the ‘AI’ would allow it to construct a more accurate map of the concepts – it would learn and evolve it’s notion of the world the same way we do.
It need not to take the shortest route. In fact it can follow a random path as our thoughs so usually do.
Of course, creating this conceptual map is only the first step. There is a large gap in going from ‘father son family’ to ‘The father and the son are a family’. One would need have a deep understanding of English to teach it to a computer program. I’d like very much a computer that I could talk to without being absolutely precise.
Why in the internet? Simply put, I believe it would be the only place large enough to store that much data. There is the liability should self-awareness emerge, however.
Well, this has been fun. A dirty python code to implement this is provided here.
[A Datacenter, unknown location. Image source]
